
Despite the growing trend to move towards Model-Based development (MBD), a large part of the automotive embedded software is still developed as handwritten code. We observe that people move to MBD methodology for new projects or when new complex functions are introduced. The remaining part of hand code could be explained by several factors: existing legacy code which has been proven in use, hand coding skills still available in the companies and the fact that it’s often difficult to reverse-engineer hand-code into models.
Although, writing embedded code in C is well established since several decades and guided by standards like MISRA C, the verification process is constantly seeking for improvements. On the pure process side, this is motivated by the new safety standards like ISO 26262 and for the daily work, engineers look for efficient solutions to test with less manual effort. Compared to the MBD, handwritten code has a smaller degree of abstraction. It’s not always easy to identify the functions and their interface variables in a bunch of source files and it’s difficult to isolate a function for testing if it has external dependencies. In this context we identify three challenges:
- The recurrent need for creating stub code for external variables and functions
- The extraction of the architecture view, meaning an abstract view of the test interfaces of each function.
- The creation of the test harness to author, execute and evaluate the test cases.
Stubbing
Isolating a function (or unit) among the software application for testing can be a tedious task if the function architecture is not appropriately defined. It’s clear that the units depend on each other through the data they exchange and sometimes they also share dependencies with sub-components like library functions, software services or hardware routines. Plus, the architecture is often distributed in several layers (or files). Therefore, setting up the test environment for one unit usually requires stub code of the variables or functions owned by other units.
Let’s look at the stubbing task from the angle of the software architecture. Let’s compare two basic types of software architectures:
a. A cluttered software architecture where the frontier between the software and the hardware layers cannot be well identified (e.g. direct call of low level hardware routines within the software units) nor the frontier between the software units (e.g. unit owning variables accessed by other units). The use of hardware functions within the unit makes it almost impossible to test the unit without the hardware. Units owning the definition of interface variables create cascaded dependencies which requires to carry several files when testing others units. Such architectures increase the stubbing effort as it’s difficult to find the cutting layer from where files, variables and functions can be stubbed.
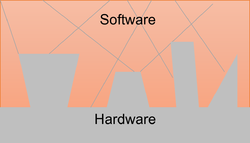
b. In contrary, a “well” structured software architecture (e.g. AUTOSAR) means that the software units are separated and communicate through interface variables not owned by the units themselves and where a middle abstraction layer creates the interface between the software and the hardware. This enables to efficiently develop and test the units individually and it significantly reduces the stubbing effort. For example, if the interface layer is not yet or only partially developed, the missing interface variables (external to the units) can be easily stubbed (in a new file) without altering the production code.
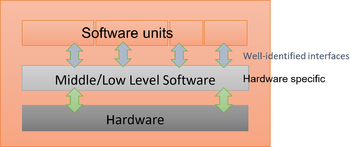
In distributed development processes, functions are developed by several teams in parallels and some parts of the architecture are only available at the integration phase therefore, stub code is needed. An appropriated software architecture reduces the stubbing effort but the complexity depends also on the data to be stubbed. Here are some examples:
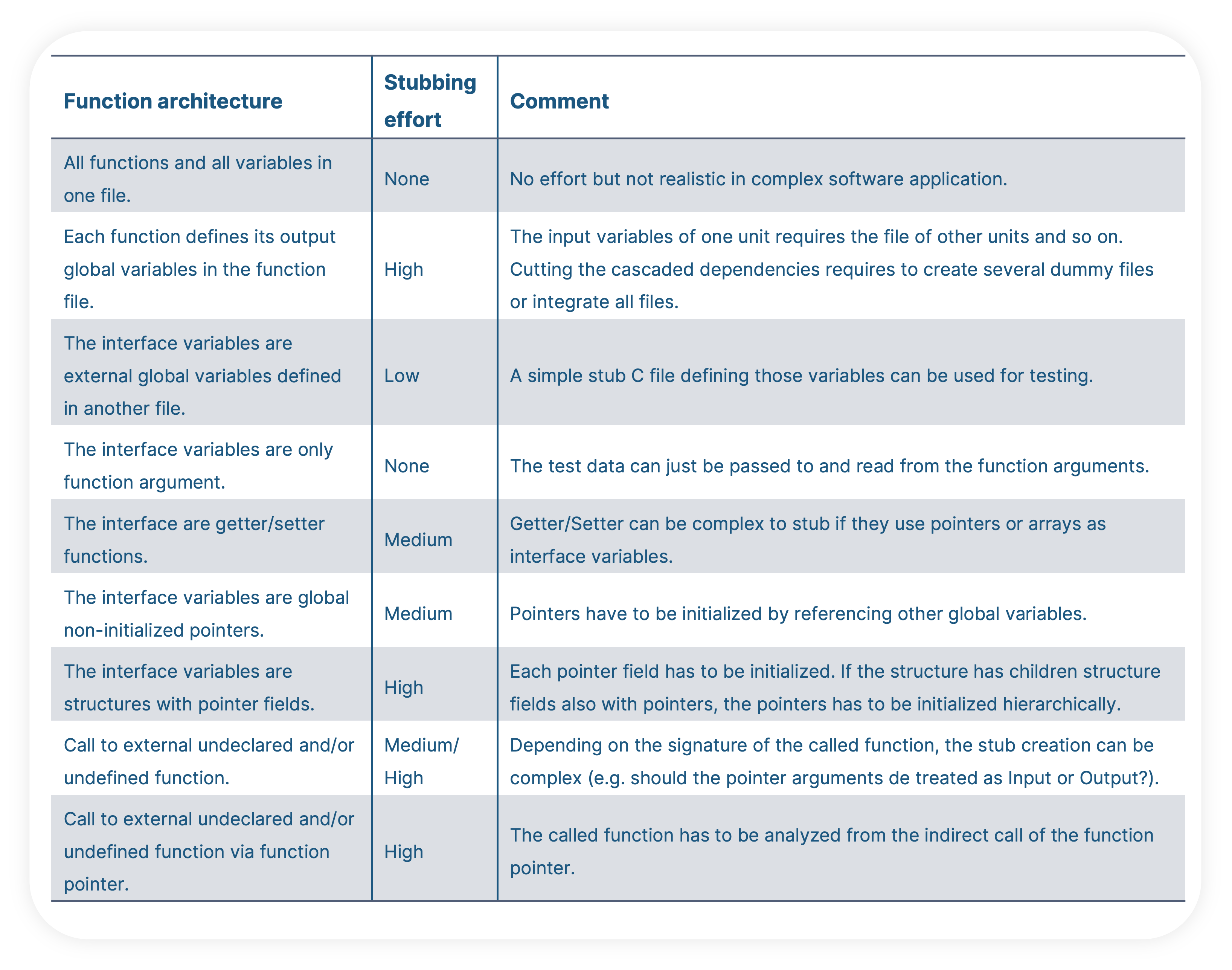
Once the software architecture allows it, the stubbing can be efficiently handled through an automated workflow which is typically assisted by tool. The correctness and accuracy of the stub code depends on the tools capability to identify the inter-dependencies within a set of source files. With BTC EmbeddedPlatform for instance, the stubbing feature proceeds to an exhaustive parsing of the c-code to detect undefined variables and functions and offer to create stub code from a simple push button. This includes stub code for arrays, pointers initialization, function pointers and complex stub code for nested structures which can be stubbed hierarchically.
Architecture definition
As a next step, let’s assume the software unit has a self-contained set of source files (including potential stub code) and is ready for testing. Before starting, two questions will pop up:
- How to identify and access the input and output variables of the unit?
- Which functions are part of the unit and how are connected?
Interface Variables
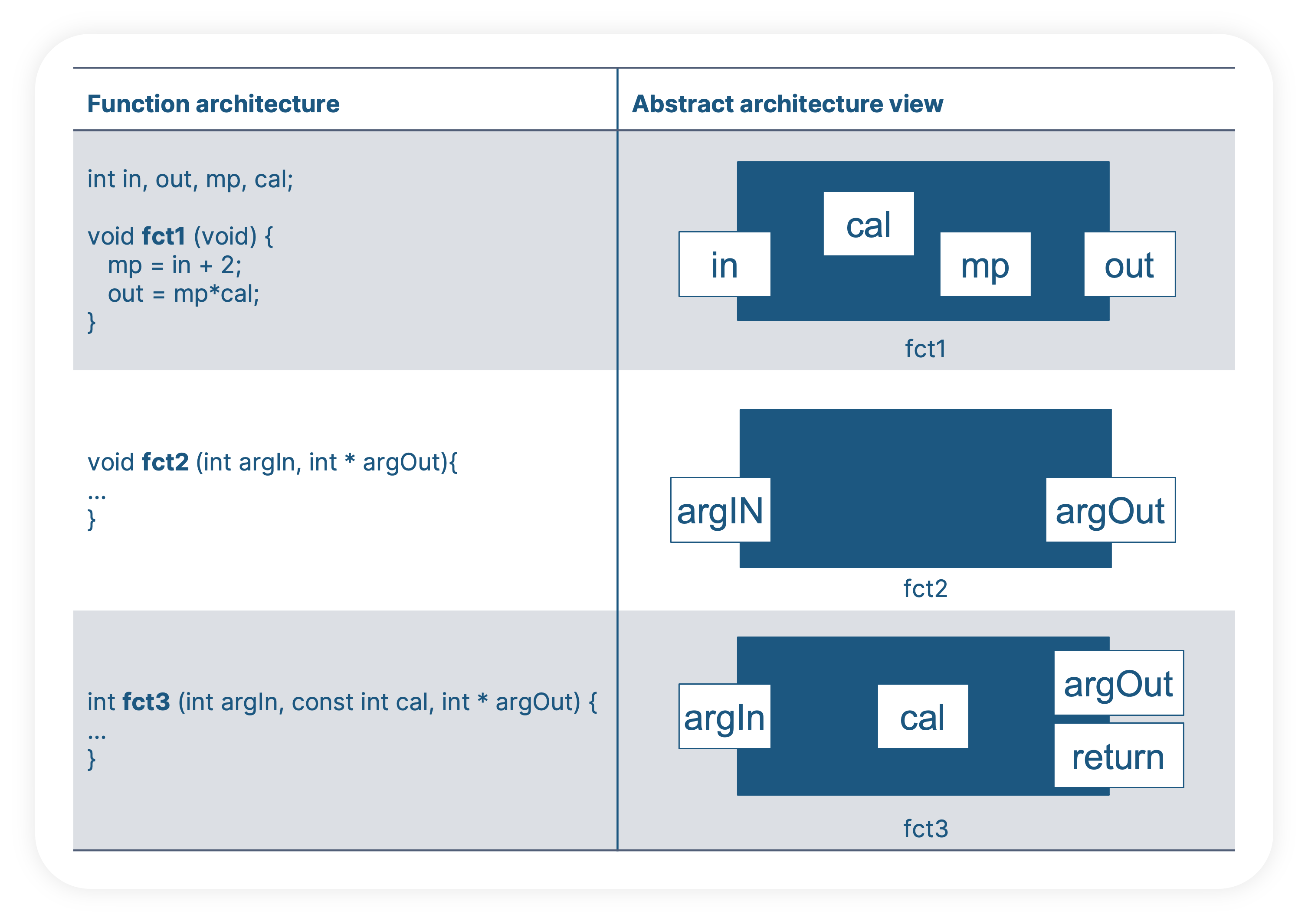
In the Model-based development, the interfaces are omnipresent in the model structure (e.g. the ports of a subsystem) but in handwritten code the information is not transparent. The test interfaces can be function arguments, global variables, getter/setter functions, macros, individual elements within composite data like structures or a mix those, and they could be defined in any file and at any line of the code. Manually looking at the code to find the information is not realistic but the test engineer could rely on the test tool to automatically extract the information based on heuristics. No matter how the function architecture is defined, having an abstract architecture view of the test interfaces is a major step in building the test project. In general, the software units have four types of interfaces:
- Input variables: signal produced by another unit and received by the unit under test
- Output variables: signal produced by the unit under test
- Calibration variables: global variables used for software configuration.
- Measurement variables: global variables inside the unit allowing to measure inner operation results usually for debugging purpose. They are sometimes also referred to as display variables or test points. For the unit test they are treated in a similar way as outputs, but they are not consumed by other units.
In the following examples, we see various definitions of function interfaces. For the test engineer, the abstract architecture view is obviously much more transparent then the code itself.

Function Hierarchy
Complex or large software units are usually split into smaller functions. The goal is to group functional operations into sub parts. It can be a pure design choice of the developer or motived by the requirements (e.g. pre or post processing of data, reusable operations, etc.). Such architectural design is very practical to break down the complexity. For the developer, it helps to develop the function step by step and for the tester, it allows to test functions of relatively small sizes (always better for the human brain) and proceed hierarchically toward the highest level. This also eases the debugging tasks as a failure cause can be narrowed down to a small area of the unit.
As for the function interfaces, it is very difficult to get the information about the function hierarchy by just looking at the C-Code. An abstract architecture view (call graph) is dramatically easier to read and understand.
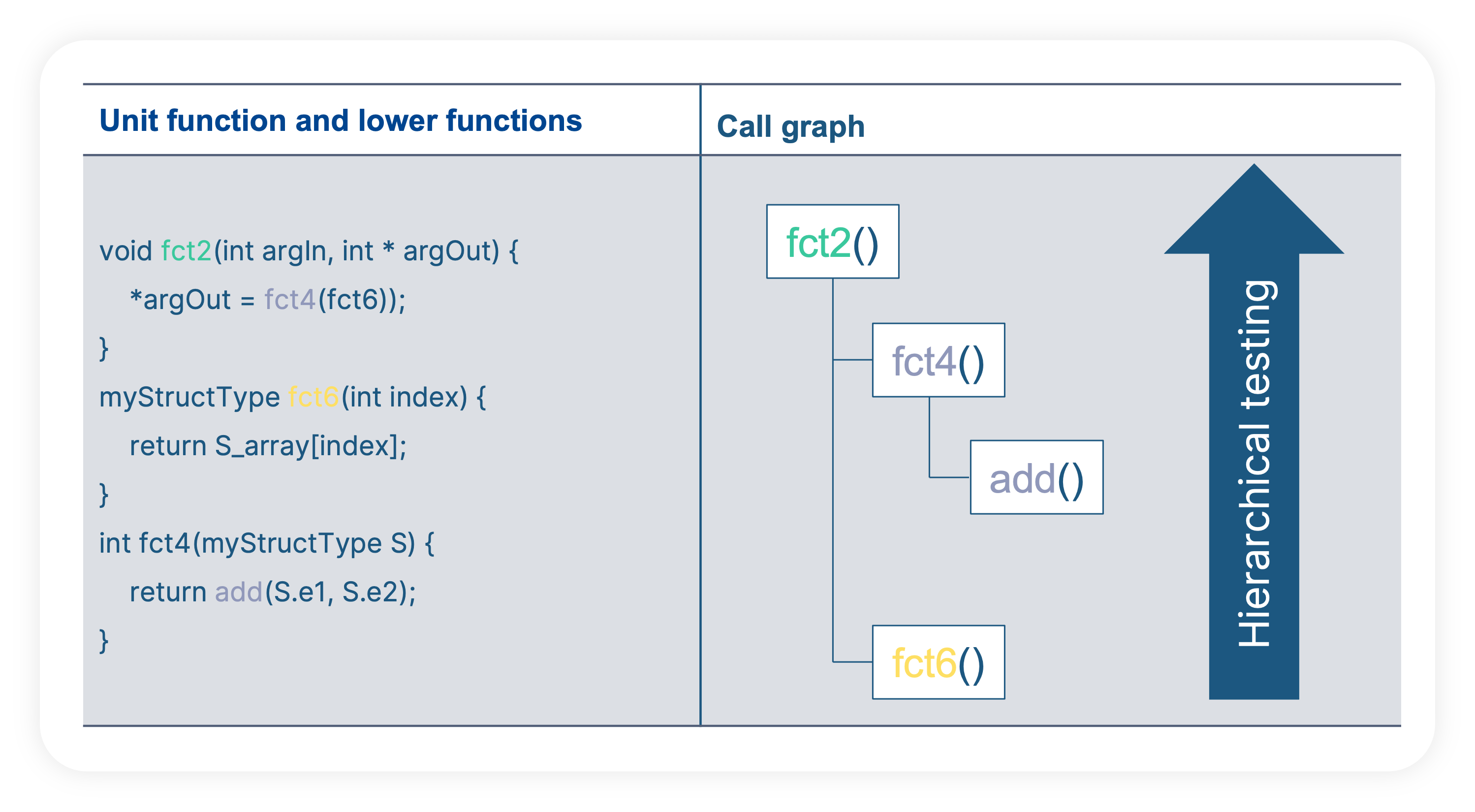
With BTC EmbeddedPlatform, the automatic analysis of the source code finds all functions and the hierarchical call between each other. This is represented in a call graph where the test engineer can select/unselect (e.g. ignore already tested functions) the functions to test. In addition, each function is analyzed in terms of test interfaces to automatically offer an abstraction view of the variables to access in the test cases. The user can adjust the proposed architecture definition or load it from external data base describing the functions I/Os and parameters.
Test Harness
The test harness is the executable environment that connects the c-function, the test cases, the compiler and further methods (or tools) to evaluate the test results. It can also handle surrounding aspects like stubbing, test management, coverage measurement, requirements traceability, debugging, etc.
The traditional approach for testing handwritten code is, to test it with handwritten code, which means to implement the test frame and the test cases in C-Code. This could be done in a C/C++ project using standard Integrated Development Environment (IDE) like Microsoft Visual Studio or Eclipse. The nice thing with an IDE is that it offers a white box view of the functions which is very convenient for debugging but the level of abstraction for writing and evaluating the test cases is very low compared to a graphical user interface. Although the main features like test creation, test execution, debugging can be achieved in the IDEs, the other aspects usually require an integration with third party tools. Nevertheless, the simple connection between the test cases and the function is already a big challenge.
Among others, the following features are often needed: the test harness should be able to interpret the scaling of the interface variables to convert physical values to integer values, enable mathematical signals creation including time dimension, enable the definition of tolerances or more or less complex verdict mechanism to evaluate the test results, execute several test cases automatically.
Using a manual approach to create a test harness is error-prone and any mistake can have a direct influence on the test results. Therefore, a pragmatic choice for testing complex software is typically to use professional tool. However, the efficiency of setting up the test project depends on the ability of the test tool to automatically create the test harness from an abstract definition of the software architecture to the actual test authoring and test execution environment. This can considerably reduce the manual tasks of the test engineer during the setup phase.
Conclusion: Automation and Abstraction are testers’ best friend.
esting handwritten code is possible with several IDEs including open source tools but for complex software applications testing goes beyond a simple gathering and compilation of source files in an IDE. Efficient testing needs a “well” defined software architecture followed by a test process with a maximum of automation and sufficient abstraction during test authoring. Stubbing is a key element and it’s usually automated in the test tool. An abstract view of functions and interfaces offer a “system” view which eases the mapping to the software requirements as well the creation of test cases. An automatic creation of the test harness, without user interaction, is the highest added value feature for a test engineer. In addition, we shouldn’t ignore additional needs like requirements traceability, coverage measurement, reporting and debugging which integrated together offer a complete test solution.

